Klepsydra ROS 2 Executor: A ring-buffer to rule them all
Our own ring buffer lock-free executor for ROS 2 is based on Klepsydra’s main product, the SDK. This performance has never been seen in an executor before.
Lock-free programming
Klepsydra is based in lock-free programming. This kind of programming is the high-level wrapper of the atomic operations in the processor, in particular the so-call compare-and-swap or CAS operation. It was invented back in the 70s, but it didn’t really become popular until the early 90s, when it was implemented in higher-level languages and then it really took off when Java included it in the early 2010s.
Lock-free programming consists of attempting repeatedly to write data in a small piece of memory until the data is in a consistent state. This is usually depicted as a plane trying to land in a busy airport. If the runway is busy, it flies away and then tries it once and again until success.
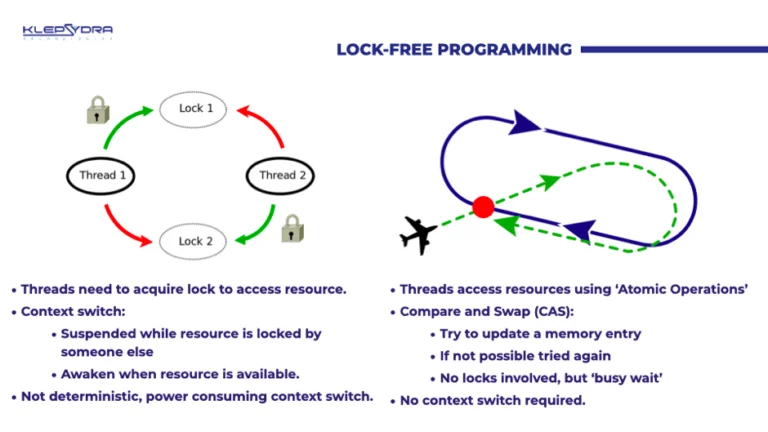
This technique is substantially lighter than the traditional mutex operation, because it is just specific to a one small piece of memory, as opposed to mutex, which blocks a big portion of the memory. That is why the traditional lock systems are not deterministic, while lock-free systems are more granular and deterministic. It works remarkably more efficient.
Klepsydra ring-buffer
Our own ring buffer is wrapped in what we call the Klepsydra SDK. It is just another library that is installed in the operating system that receives data from multiple sources. It is essentially a memory sharing system.
Our ring-buffer is enabled for two different approaches to data processing:
-
The sensor multiplexer uses the ring buffer to process the same data multiple times simultaneously. One producer of data, usually large volumes like a camera or a LiDAR, and multiple consumers. The advantage of this approach is that consumers are able to process data at different rates, completely independent of each other. The sensor multiplexer ensures that the data remains consistent, so the consumers have access to the data while it is being used. Once the consumer is finished, the multiplexer will provide it with the most recent data to process further.
-
The event loop uses the ring buffer to process, in a single consumer, data coming simultaneously from multiple sources. Producers can publish to the event loop at different rates, completely independent of each other. The ring- buffer streamlines all this data and delivers it into a single threaded consumer. This data flow process has a very low latency. These two approaches have two main advantages:
Very low power consumption. A large throughput of processed data.
Klepsydra ROS 2 executor
Our first lock free executor implementation for ROS 2 is built on top of the event loop. Every ROS 2 publisher, also called advertiser, is connected to a ring-buffer producer. The timers are connected as well to the schedulers in the event loop. Lastly, the ROS 2 subscribers are connected to the single threaded consumers.
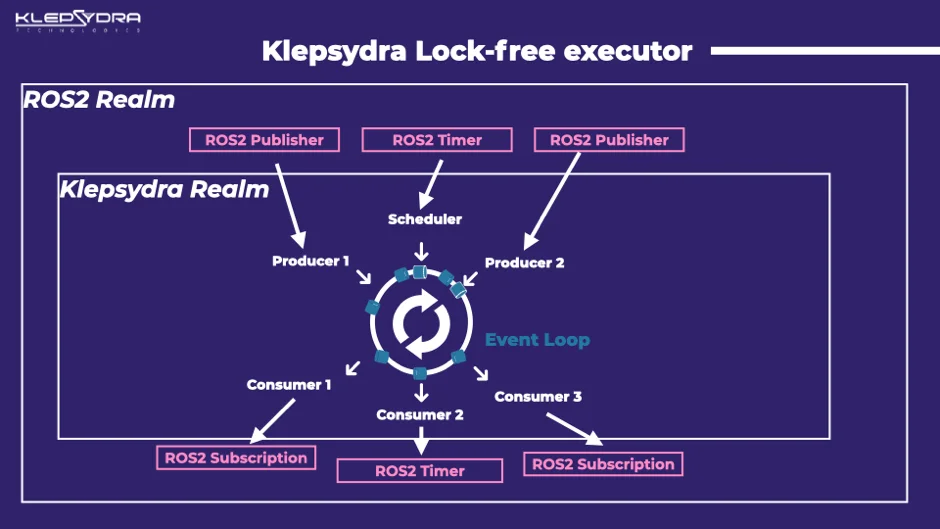
Our event loop follows a similar design pattern to NodeJS Event Emiter. Although Klepsydra implementation is completely different, the behaviour is the same as all the events happen in one thread. Since the timers and subscriptions are single threaded, there is no need to use any locks.
Current issues in ROS 2
Looking into the issues in ROS 2, two of them can be finally solve by Klepsydra’s ROS 2 executor:
High CPU usage of the default ROS 2 executor. When large volumes of data or high frequency data is being placed into the ROS 2 executor, the CPU consumption grows very fast. (https://github.com/ros2/rclcpp/issues/1637). The ROS 2 executor becomes unstable when large point Cloud data is connected to many subscribers. One producer of this kind of data with many subscribers drop messages without discrimination, with the risk of losing critical data. (https://github.com/ros2/rmw_cyclonedds/issues/292) Testing scenarios were built for the above-mentioned issues and then validated in a Raspberry Pi 4. Three executors were examined under these testing scenarios:
- The static single threaded.
- The multi-threaded executor.
- Klepsydra’s executor. In the first test scenario, the results proved that Klepsydra’s executor needs substantially less CPU consumption with moderate data rates. As the number of publishers increases and the data rate gets faster, the difference in CPU consumption becomes considerably large. At a certain point, it can be observed that only Klepsydra processes all the incoming messages, whereas the other two executors cannot keep up and start losing critical data.
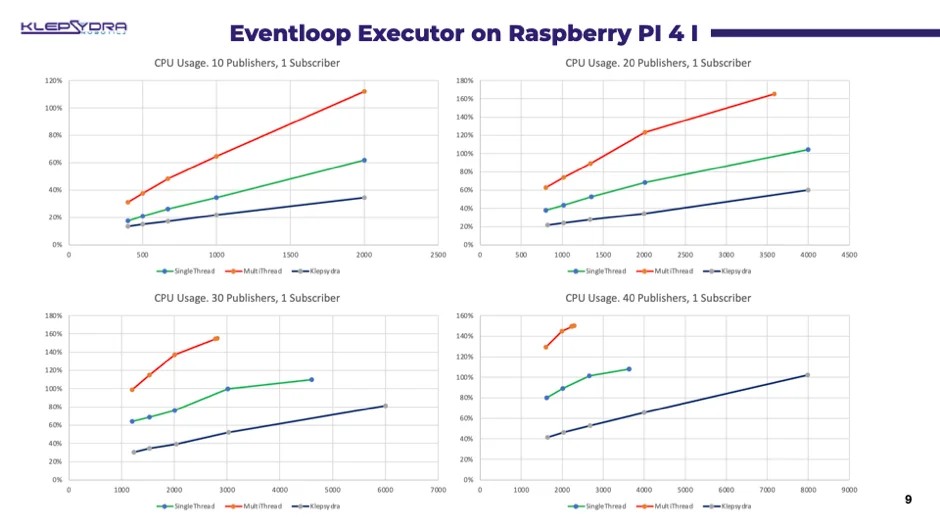
As for the second test case, with the introduction of multiple subscribers per publisher, the obtained results were even better. The Klepsydra lock-free executor can process substantially more volumes of data. Where the other executors stop processing data, Klepsydra continues until the physical limit of the computer, utilising the available resources in an optimal manner.